DMN
DMN















































































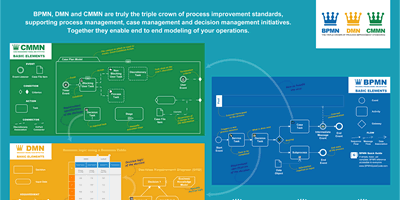
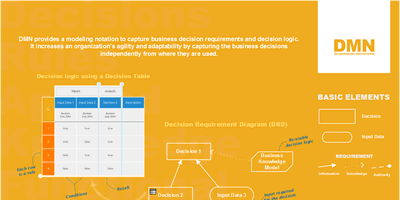









Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting
We would like to use third party cookies to improve the functionality of this website.