

I gave a conference presentation recently that included a discussion on the business imperatives of agility and scalability: agility is necessary for innovation, while scalability is necessary for survival, and both business agility and scalability must be supported and enabled by technology. Later, I had a discussion with one of the attendees on agility and scalability; his fundamental question was how organizations are measuring these two capabilities. Excellent question! In my experience, these are often “measured” only after a failure mode is experienced, that is, the organization fails (usually catastrophically) to be sufficiently agile or sufficiently scalable.
Agility needs to be baked in during the design phase, and often rests on design decision such as the split between process and decision logic. It used to be the case that processes and decisions were designed independently, usually by completely different groups. If they could be used together, that was often a happy accident rather than by design. I would joke that if you gave the same process/decision automation problem to a process analyst and a decision analyst, the process analyst would model all decisions as tree-like structures within a process model, while the decision analyst would create a single-step process model that called a decision model to do all the work. Although a (slight) exaggeration, this is an example of Maslow’s hammer: the cognitive bias towards a tool that you know versus one with which you are less familiar, or in the common vernacular, “when all you have is a hammer, everything looks like a nail”.
Nowadays, best practices are dictating that “business automation” analysts and centers of excellence consider multiple technologies together when designing new business models and applications, especially the interplay of processes and decisions. You have to understand the strengths and weaknesses of both process and decision models (and their underlying engines) to know how to properly design most business applications. This means, however that anyone viewing the models – from business people to technical developers – needs to be familiar with both the process and decision model notations, and how they interact.
Assuming that you’re using model-driven process and decision management systems (BPMN and DMN, respectively) for design and implementation, you might assume that it doesn’t really matter how you design your applications, since either could be quickly changed to accommodate changing business needs. It’s true that model-driven process and decision management systems give you agility in that they can be changed relatively quickly with little or no coding, then tested and redeployed in a matter of hours or days. But your design choices can impact understandability of the models as well as agility of the resulting application, and it’s important to have both.
Process models are a natural way to visualize any process-based application, and often the starting point when thinking about a new application or understanding a business function: business people, analysts and developers think about the business in terms of how the work flows from one stage to the next. Decisions, however, are an integral part of that: at any point in a process, a decision may be made about which path to take next, or how to evaluate or calculate the work in progress. The decisions are often some of the “details” of how a business function is completed, and likely will be of greater interest to people within that business area than those trying to get a broader view of the end-to-end process.
A common design method is to create a process model first to show the overall flow of activities, then design decisions as specific calculation steps within that process. For example, a person inputs some information, then a calculation is made using a decision model, then a service call updates the system of record:
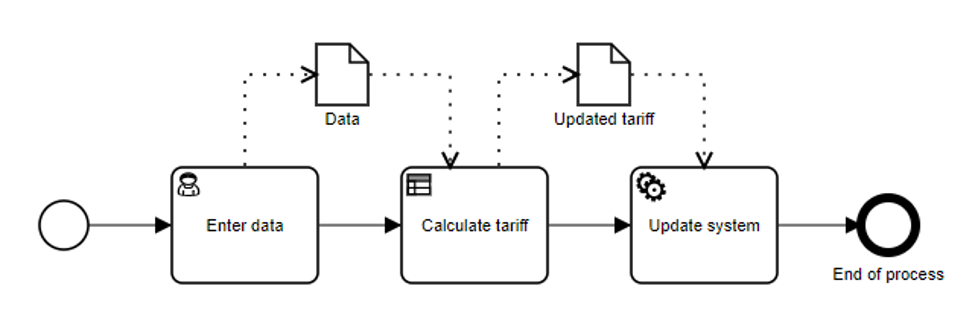
The details of how the decision is made is not visible in the process model since that’s not relevant to the flow of work: it is making a calculation as part of the process, and the output data from the decision is used by a later step. It’s also quite clear to most analysts that this decision should be encapsulated in a separate decision model, the details of which will be relevant to those responsible for the accuracy of those decisions, but not necessarily to all viewers of the process model.
A decision may also be used to control the flow within a process, such as determining the customer status and sending the work to the correct group:
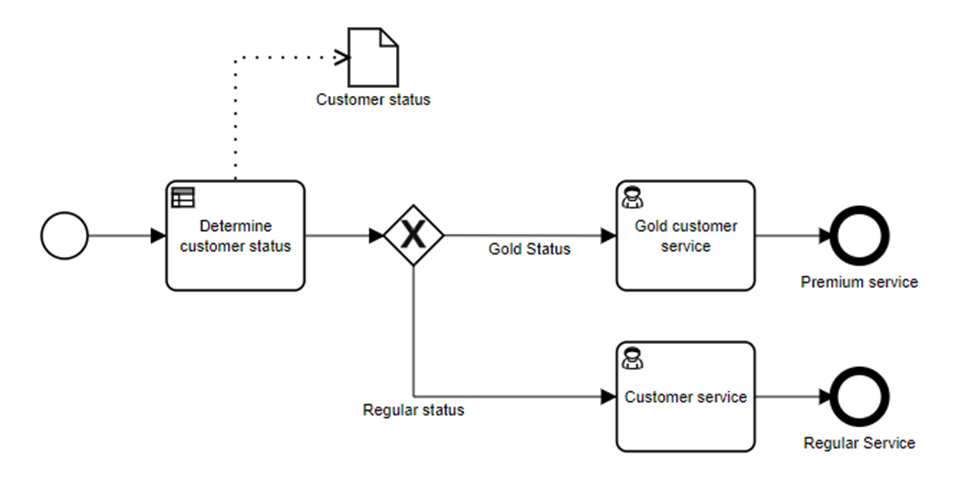
In this case, the decision determines a data value (is the customer gold level or not) which is then used in the gateway immediately following the decision task in order to control the process flow. It’s not quite so obvious to many analysts that this should be a separate decision, however, and some would model it as branching logic within the process itself:
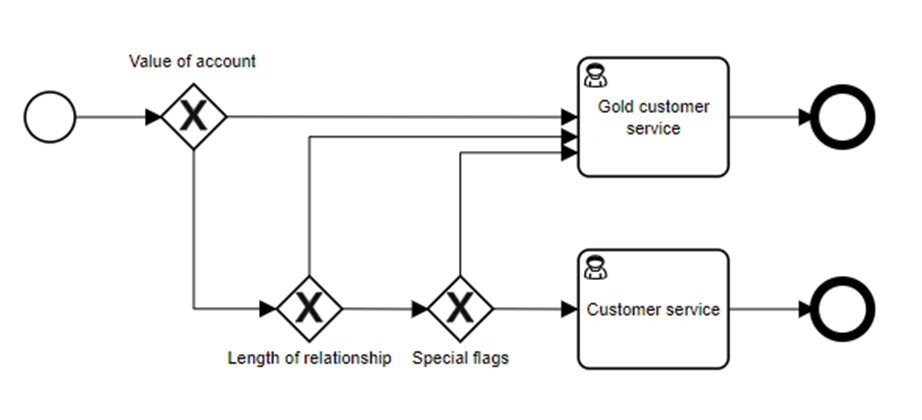
Comparing these latter two functionally-equivalent models, why would you choose to add a decision model (and engine) instead of “keeping it simple” by having everything in the process model? There are a few reasons for this:
Reusability. Putting the decision in a decision model makes it reusable. If other applications – whether or not they are implemented using process models – need to use the same decision, it’s available.
Complexity and model understanding. As the decision logic becomes more complex, the process tree version of it will become large and difficult to follow; eventually, it will not be possible to implement the decision as a process model. However, if a decision is simple branching logic that is localized to a process, moving it to a separate decision model may reduce the businesses’ ability to understand the models without improving agility.
In-flight updates. When an application is based on a model-driven process engine, each new case (process instance) takes a copy of the then-current process model at the time that it is created; if the process model changes before this particular case completes, its process model will still follow the original path. Any decisions that it calls, however, can be the most up-to-date version of the decision at the time that the specific decision activity is executed, or can use the version that was in force at the time that the case was created. In other words, changes to your process models may take time to propagate through the system, while changes to your decision models can be instantaneous. If your processes are relatively short-running, and complete within a day or two, this is rarely a problem. However, if a single case may stay active for many days, weeks or months, you need to consider the agility of these in-flight processes. Although some BPMS products allow you to migrate in-flight process instances when the process model changes, if there are significant change to the model, it may not be possible to migrate everything; some instances will have to be hand-migrated or allowed to run their course using the old model.
Going back to the original question about measuring agility of an organization, the use of model-driven process and decision management systems definitely improves agility over traditional coding methods. But it’s also critical to combine the process and decision models in the right way, since that will impact the businesses’ ability to understand and contribute to those models, and therefore shorten the time required to move from business need to operational system.













































































































































Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting