

A couple of posts ago, I talked about Conway’s Law, and how functional silos can cause a lot of problems within an organization.
That post was about aligning business goals and departmental metrics, and I wanted to take a more technical look at how to integrate these functional silos into end-to-end processes, and how to maximize scalability and flexibility. Since that time, however, a disruptive event intervened in the form of a global pandemic, which has thrown a spotlight on fragile business processes that experience cascading failures when something unexpected happens. We’re seeing this now with supply chains, where goods aren’t moving to where they are required not only because of problems with the manufacturing process, but due to breakdowns in fulfillment and shipping processes. Having the ability to change the later stages of an end-to-end process on the fly is necessary for “routing around” these types of failures, and requires a different approach to how we design processes.
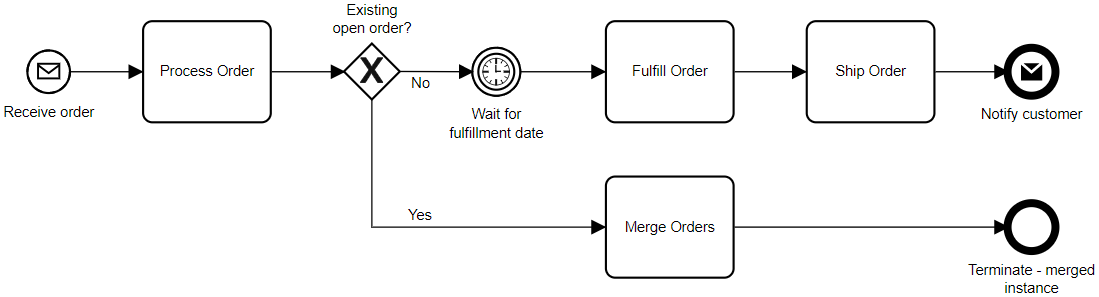
In that first post, I used an order-to-cash process as an example, where each of the blocks represents a different function performed by a different department. I’ve simplified it further here to show more of a consumer online ordering flow, like what you would see when you order from Amazon.

This, however, is an overly simplistic view of the actual process: is the entire end-to-end process a single, tightly-coupled orchestrated process, such as is implied by the diagram above? Probably not, and you probably don’t want it to be.
A process analyst might start by assuming that the end-to-end process is a single work stream to be executed, with each order resulting in single fulfillment and shipping activities. If you’ve ever placed a complex online order, you know that’s not how it works: a single order can be split based on when the items are available, then split further into shipping packages if they are being fulfilled in different locations or require different shipping methods. Although some companies will wait until every thing in your order is in one place so that they can send it out in a single box, the big online retailers know that it’s more efficient to break the order down into groups of items that can be fulfilled and shipped together.
That’s a bit of a wrinkle in the process model, but we can handle that with multi-instance activities for fulfillment and shipping, once the front-end processing has broken the order down into the unique shipments.

However, to complicate things further, multiple orders for the same customer can end up being consolidated at the time of fulfillment and/or shipping, then shipped as a single package. This consolidation pattern is a bit trickier to handle, since we don’t know at the beginning of the process whether this instance will result in a package being shipped, or if it will end up being merged into another order. Instance consolidation is a fairly common use case, where you want multiple inbound events from the same customer to result in a single outcome, rather than one outcome per inbound event. This is often handled poorly by just not bothering to consolidate: multiple outcomes are generated for the same customer for things that could have been done as a single outcome.
If we ignore the previously-mentioned order splitting and consider only the consolidation, you can still map this as a straight-through orchestration, although it depends on that that gateway labelled “Existing open order?” which checks if the customer (and shipping address) for this order matches another one that is already in progress. If so, the data from this order is merged into the existing instance to be handled as a single order for the purposes of fulfillment and shipping, and this instance terminates.
To go back to the problem of how to handle disruption in parts of the process, we need to split this up so that the processing, fulfillment and shipping are different processes that can be managed separately.
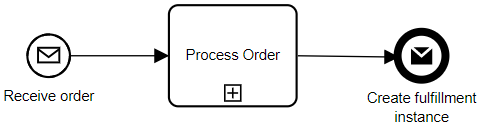
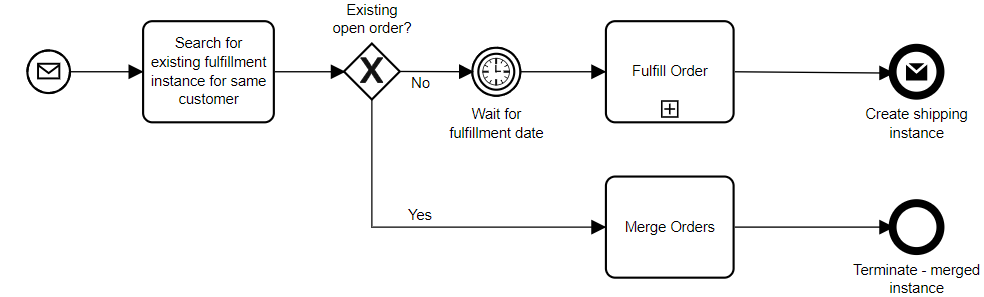
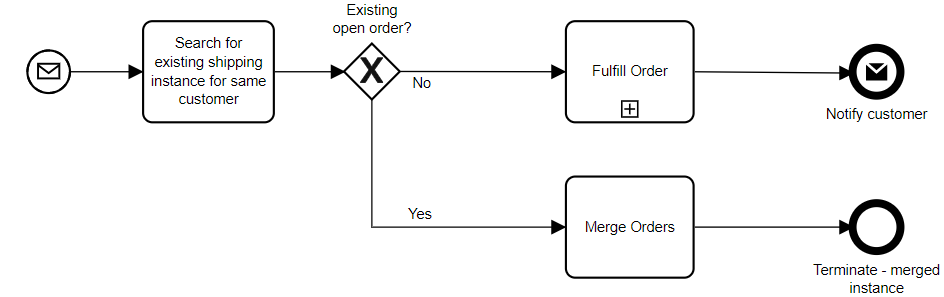
This is a highly simplified model, but you get the idea: the three main “capabilities” within our process are executed as separate processes, connected by events. This is more of a choreography than an orchestration (although orchestration exists within each of the three processes), with the agility to make changes to any of the three processes independently of each other. In effect, each of these processes is like a microservice; in fact, depending on your BPMS, they may be implemented as microservices, which would have the added benefit of providing independent scalability for each of the processes.
If we think back to functional silos, however, we need to ensure that we maintain a view of the end-to-end process, or we risk losing sight of the organizational metrics that help us to overcome Conway’s Law. Going back to my post on that topic, I wrote “having a model of the end-to-end business process does not mean that the process is a tightly-coupled orchestration in the underlying systems: the actual implementation may be an event-driven choreography of microservices, or use message queues between business functions”. In most complex cases, decomposing your end-to-end process into this type of event-driven choreography makes for a much more flexible and scalable business process.













































































































































Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting