

This month we return to a topic I've written about twice before, data validation in DMN models. This post, in which I will describe a third method, is hopefully the last word.
Beginning decision modelers generally assume that the input data supplied at execution time is complete and valid. But that is not always the case, and when input data is missing or invalid the invoked decision service returns either an error or an incorrect result. When the service returns an error result, typically processing stops at the first one and the error message generated deep within the runtime is too cryptic to be helpful to the modeler. So it is important to precede the main decision logic with a data validation service, either as part of the same decision model or a separate one. It should report all validation errors, not stop at the first one, and should allow more helpful, modeler-defined error messages. There is more than one way to do that, and it turns out that the design of that validation service depends on details of the use case.
The first method, which I wrote about in April 2021, uses a Collect decision table with generalized unary tests to find null or invalid input values, as you see below. When I introduced my DMN training, I thought this was the best way to do it, but it's really ideal only for the simple models I was using in that training. That is because the method assumes that values used in the logic are easily extracted from the input data, and that the rule logic is readily expressed in a generalized unary test. Moreover, because an error in the decision table will usually fail without indicating which rule had the problem, the method assumes a modest number of rules with fairly simple validation expressions. As a consequence, this method is best used when:
- There are just a few elements to be validated
- Elements to be validated are either input data or top-level components of input data
- An element's validation rule may depend on the values of other elements
- You want the validation service to return a normal result, with a list of error messages, when validation errors are present.

The second method, which I wrote about in March 2023, takes advantage of enhanced type checking against the item definition, a new feature of DMN1.5. Unlike the first method, this one returns an error result when validation errors are present, but it returns all errors, not just the first one, each with a modeler-defined error message. Below you see the enhanced type definition, using generalized unary tests, and the modeler-defined error messages when testing in the Trisotech Decision Modeler. Those same error messages are returned in the fault message when executed as a decision service. On the Trisotech platform, this enhanced type checking can be either disabled, enabled only for input data, or enabled for input data and decisions.

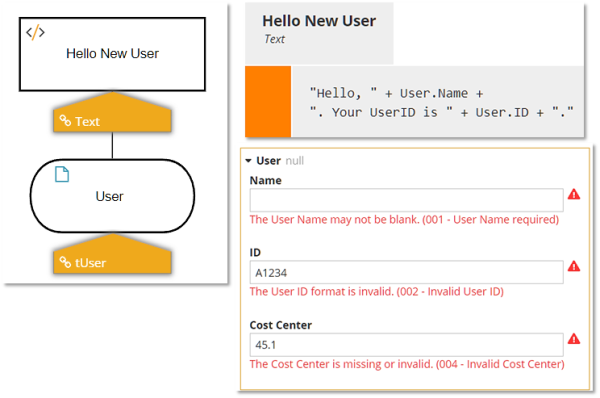
This method of data validation is avoids many of the limitations of the first method, but cannot be used if you want the decision service to return a normal response, not a fault, when validation errors are present. Thus it is applicable when:
- There could be many elements to be validated
- Elements to be validated could be deeply nested components of the input data, or variables generated by model decisions
- An element's validation rule depends only on a generalized unary test referencing its own value or the values of direct siblings, not a complex value expression of many elements
- You want the validation service to return an error result when validation errors are present, but with friendly modeler-defined error messages.
More recently I have been involved in a large data validation project in which neither of these methods are ideal. Here the input data is a massive data structure containing several hundred elements to be validated, and we want validation errors to generate a normal response, not a fault, with helpful error messages. Moreover, data values used in the rules are often buried deeply within the structure and many of them recurring, so simply extracting their values properly is non-trivial. Think of a tax return or loan application. And once you've extracted the needed data values, the validation rules themselves may be complex, depending on conditions of many other variables in the structure.
For these reasons, neither of the two methods described in my previous posts fit the bill here. Because an element's validation rule can be a complex expression involving multiple elements, this rules out the type-checking method and is a problem as well for the Collect decision table. Decision tables also add the problem of testing. When you have many rules, some of them are going to be coded incorrectly the first time, and if a rule returns an error the whole decision table fails, so debugging is extremely difficult. Moreover, if a rule fails to return the expected result, you need to be able to determine whether it's because you have incorrectly extracted the data element value or you have incorrectly defined the rule logic. Your validation method needs to separate those concerns.
This defines a new set of requirements:
- There are very many elements to be validated
- Elements may be deeply nested in the input data
- Elements may be recurring, and you need to know which instance has the error
- An element's validation logic may be quite complex and depend on the values of several other elements
- You want the validation service to return a normal result when validation errors are present, with friendly modeler-defined error messages.
The third method thus requires a more complex architecture, comprising:
- A data extraction service, a context with one context entry per data element extracted from the complex input data structure. You only need to extract variables referenced in the validation rules.
- A rules service, another context, one context entry per validation rule, reporting the RuleID, value of the tested element, and a Boolean value to indicate whether valid or not. It could possibly also output the error message, or that could be looked up from a separate table based on the RuleID.
While overkill for simple validation services, in complex validation scenarios this method has a number of distinct advantages over the other two:
- Data extraction can be tested independently of the rules. You defer rules testing until data extraction has been thoroughly tested.
- Complex data extraction logic is not limited to literal expressions using generalized unary tests, but can take advantage of contexts, BKMs, and other powerful DMN features.
- Rule logic can assume correctly extracted data.
- A single rule may reference multiple extracted elements.
- Complex rule logic is not limited to literal expressions using generalized unary tests, but can take advantage of contexts, BKMs, and other powerful DMN features.
- Errors in a context are more easily isolated and debugged than errors in a decision table rule.
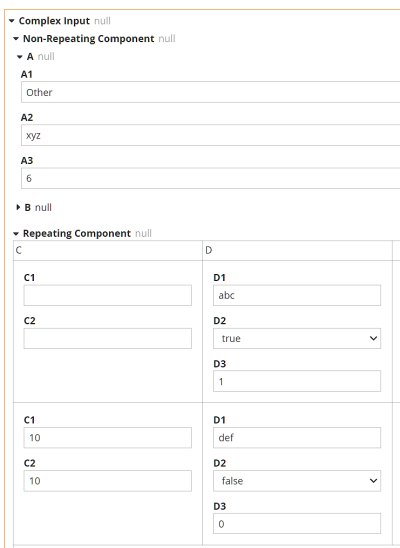
Let's walk through this third data validation method. We start with the Extraction service. The input data Complex Input has the structure shown here:
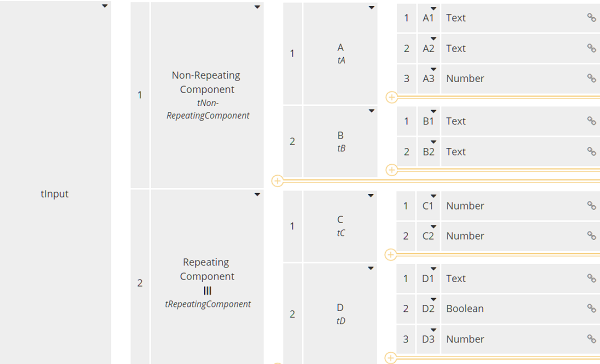
In this case there is only one non-repeating component, containing just two child elements, and one repeating component, also containing just two child elements. In the project I am working on, there are around 10 non-repeating components and 50 repeating components, many containing 10 or more child elements. So this model is much simpler than the one in my engagement.
The Extraction DRD has a separate branch for each non-repeating and each repeating component. Repeating element branches must iterate a BKM that extracts the individual elements for that instance.
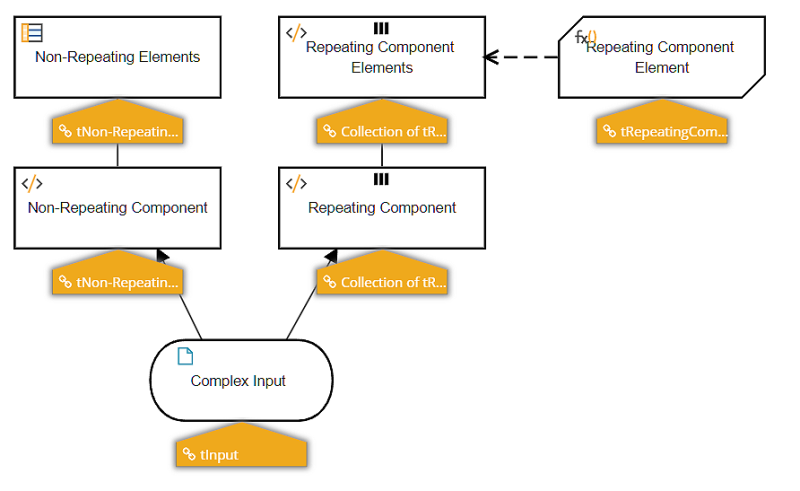
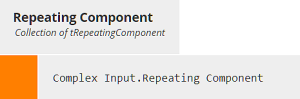
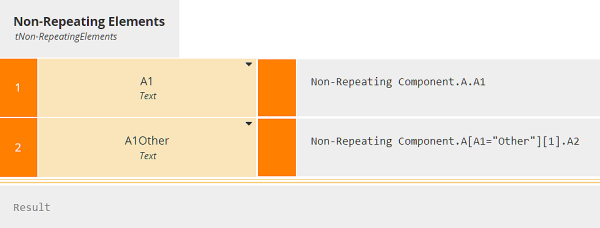
The decisions ending in "Elements" extract all the variables referenced in the validation rules. These are not identical to the elements contained in Complex Input. For example, element A1 is just the value of the input data element A1, but element A1Other is either the input data element A2, if the value of A1 is "Other", or null otherwise.
Repeating component branches must iterate a BKM that extracts the variable from a single instance of the branch.
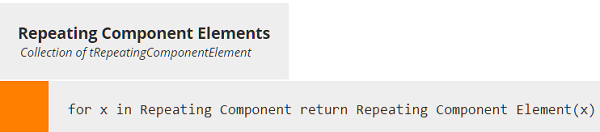

In this case, we are extracting three variables - C1, AllCn, and Ctotal - although AllCn is just used in the calculation of Ctotal, not used in a rule. The goal of Extraction is just to obtain the values of variables used in the validation rules.
The ExtractAll service will be invoked by the Rules, and again the model has one branch for each non-repeating component and one for each repeating component. Encapsulating ExtractAll as a separate service is not necessary in a model this simple, but when there are dozens of branches it helps.

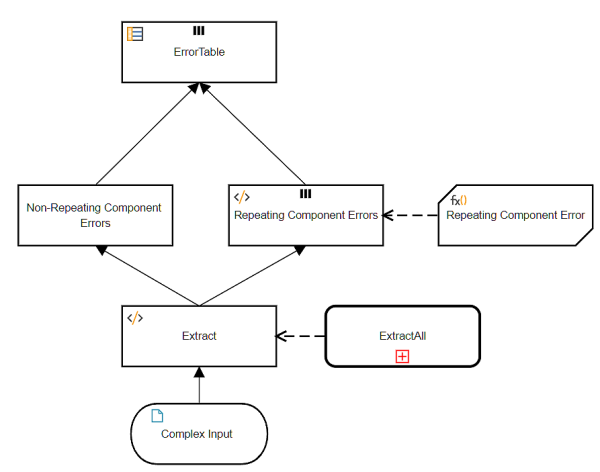
Let's focus on Repeating Component Errors, which iterates a BKM that reports errors for a single instance of that branch.

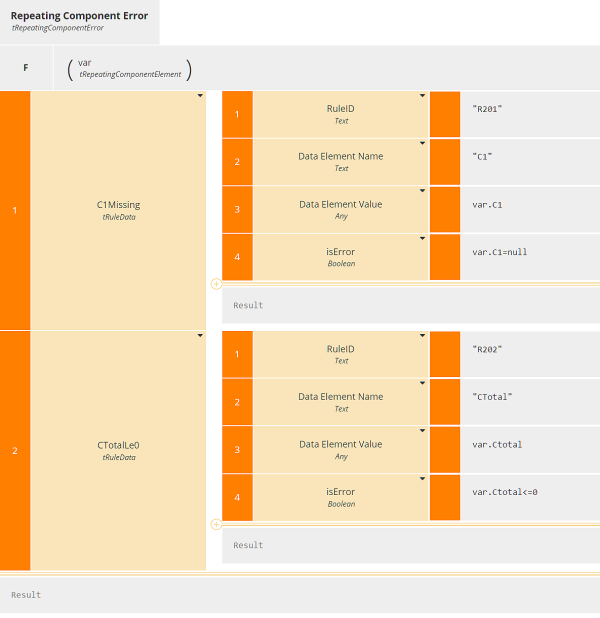
In this example we have just two validation rules. One reports an error if element C1 is null, i.e. missing in the input. The other reports an error if element Ctotal is not greater than 0. The BKM here is a context, one context entry per rule, and all context entries have the same type, tRuleData, with the four components shown here. We could have added a fifth component containing the error message text, but here we assume that is looked up from a separate table based on the RuleID.
So the datatype tRepeatingComponentError is a context containing a context, and the decision Repeating Component Errors is a collection of a context containing a context. And to collect all the errors, we have one of these for each branch in the model.
That is an unwieldy format. We'd really like to collect the output for all the rules - with isError either true or false - in a single table. The decision ErrorTable provides that, using the little-known FEEL function get entries(). This function converts a context into a table of key-value pairs,and we want to apply it to the inner context, i.e. a single context entry of Repeating Component Error.

It might take a minute to wrap your head around this logic. Here fRow is a function definition - basically a BKM as a context entry - that converts the output of get entries() into a table row containing the key as a column. For non-repeating branches, we iterate over each error, calling get entries() on each one. This generates a table with one row per error and five columns. For repeating branches, we need to iterate over both the branches and for the errors in each branch, an iteration nested in another iteration. That creates a list of lists, so we need the flatten() function to make that a simple list, again one row per error (across all instances of the branch) and five columns. In the final result box, we just concatenate the tables to make one table for all errors in the model.
Here is the output of ErrorTable when run with the inputs below:
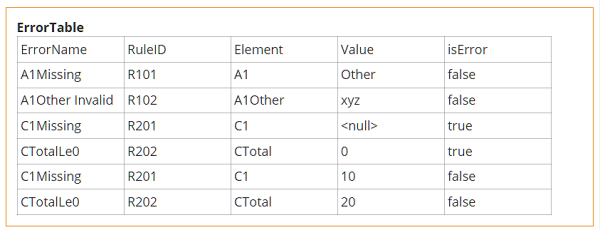
ErrorTable as shown here lists all the rules, whether an error or not. This is good for testing your logic. Once tested, you can easily filter this table to list only rules for which isError is true.
Bottom Line: Validating input data is always important in real-world decision services. We've now seen three different ways to do it, with different features and applicable in different use cases.
Follow Bruce Silver on Method & Style.













































































































































Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting