

In BPMN Method and Style, which deals with non-executable models, we don't worry about process data. It's left out of the models entirely. We just pretend that any data produced or received by process tasks is available downstream. In Business Automation, i.e., executable BPMN, that's not the case.
Process data is not pervasive, available automatically wherever it's needed. Instead it "flows", point to point, between process variables shown in the diagram and process tasks. In fact, data flow is what makes the process executable. With most BPMN tools, defining the data flow requires programming, but Trisotech borrows boxed expressions and FEEL from DMN to make data flow - and by extension, executable process design - Low-Code. This post explains how that works.
First, we need to distinguish process variables from task variables. Process variables are shown in the BPMN diagram, as data inputs, data outputs, and regular data objects. A data input signifies data received by the process from outside. When we deploy an executable process as a cloud service, a data input is an input parameter of the API call that triggers the process. Similarly, a data output is an output parameter of the API call, the response. A data object is a process variable created and populated within a running process.
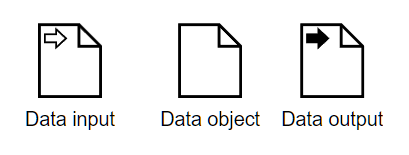
Task variables are not shown in the process diagram. They are properties of the tasks, and the BPMN spec does not specify how to display them to modelers. What is shown in the diagram are data associations, dotted arrows linking process variables to and from process tasks. A data input association from a process variable to a task means a mapping exists between that variable and a task input. Similarly, a data output association from a task to a process variable means a mapping exists between a task output and the process variable.The internal logic of each task, say a decision service or external cloud service, references the task variables. It makes no reference to process variables.
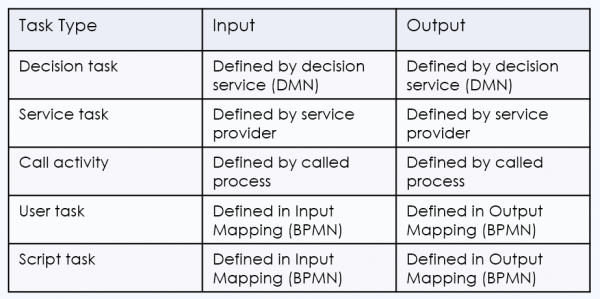
On the Trisotech platform, the task inputs and outputs are shown in the Data Mapping boxed expressions in the task configuration. Task variable definitions depend on the task type. For Service tasks, Decision tasks, and Call Activities, they are defined by the called element, not by the calling task. For Script and User tasks, they are defined within the process model, in fact within the Data Mapping configuration.
A Service task calls a REST service operation. The Operation Library in the BPMN tool provides a catalog of service operations available to the Service tasks in the process. Operation Library entries are typically created by the tool automatically by importing an OpenAPI or OData file from the service provider, but they can also be created manually from the API documentation. Each entry in the Operation Library specifies, among other details, the service input and output parameters. When you bind a Service task to an entry in the Operation Library, the Service task inputs are the service's input parameters and the Service task outputs are the service's output parameters.
A Decision task calls a DMN decision service on the Trisotech platform. In the DMN model, you create the decision service, specifying the output decisions, which become the service outputs, and the service inputs, which could be input data or supporting decisions. When you bind a Decision task to the decision service, the service inputs become the Decision task inputs and the service outputs become the Decision task outputs.
A Call Activity calls an executable process on the Trisotech platform. When you bind the Call Activity to the called process, the data inputs of the called process become the task inputs of the Call Activity, and the data outputs of the called process become the task outputs of the Call Activity.
With Service tasks, Decision tasks, and Call Activities, the task inputs and outputs are given. They cannot be changed in the calling process. It is not necessary for process variables in the calling process to have the same name or data type as the task variables they connect to. All that is required is that a mapping can be defined between them.
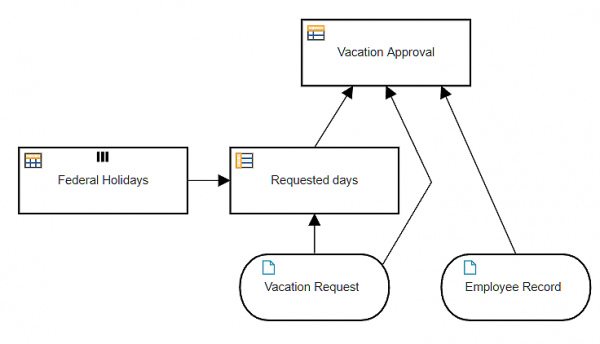
Let's look at some examples. Below we see the DRD of a decision model for automated approval of an employee vacation request, and below that the decision service definition, Approve Vacation Request.
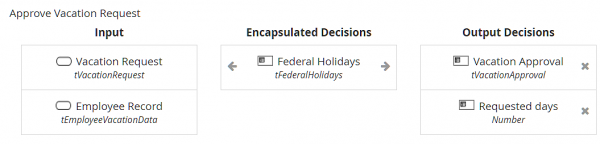
In BPMN, the Decision task Approve Vacation Request is bound to this decision service.
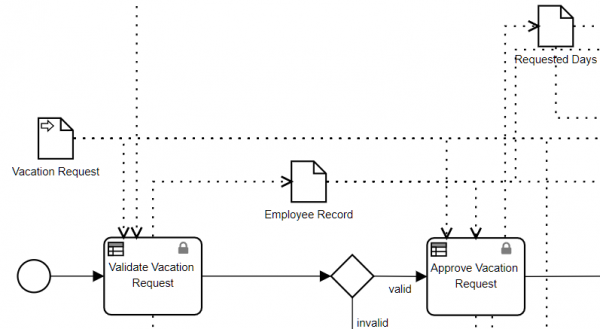
Here you see the process variables Vacation Request (data input), Employee Record (data object), and Requested Days (data object). Vacation Request and Employee Record have data input associations to the Decision task. There is a data output association to Requested Days and two more to variables not seen in this view.
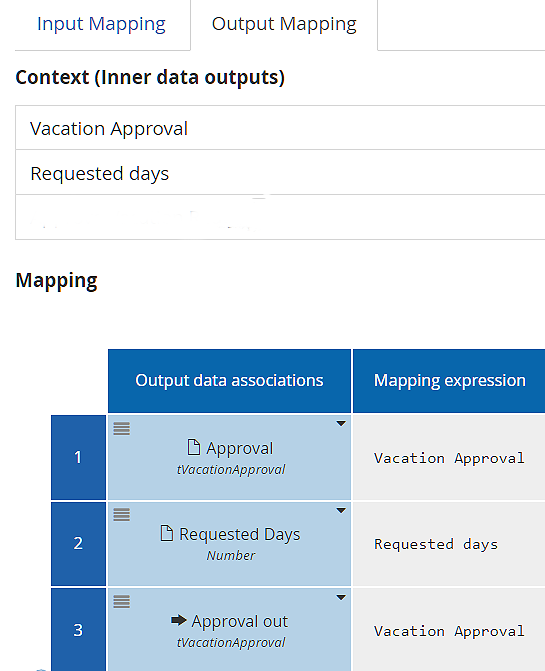
The Data Mapping dialog of Approve Vacation Request shows the mapping between the process variables and the task inputs and outputs. Remember, with Decision tasks, the task inputs and outputs are determined already, as the input and output parameters of the decision service. In the Input Mapping below, the task inputs are shown in the Mapping section, labeled Inner data inputs. The process variables with data input associations are listed at the top, under Context. The Mapping expression is a FEEL expression of those process variables. In this case, it is very simple, the identity mapping, but that is not always the case.
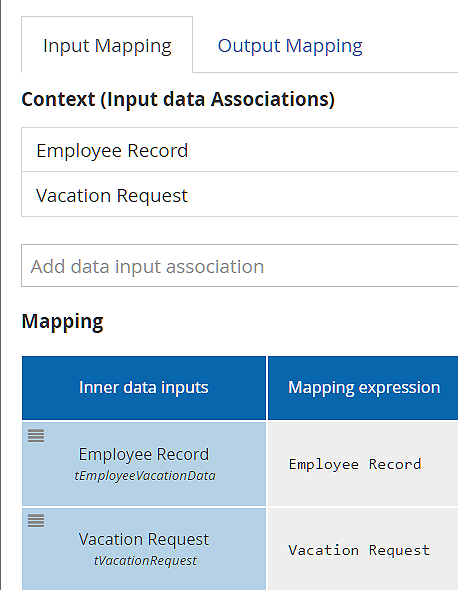
In the Output Mapping below, the task outputs are shown in the Context section, and the process variables in the first column of the Mapping section. The Output Mapping is also quite simple, except note that the task output Vacation Approval is mapped to two different process variables, Approval and Approval out. That is because a process data output cannot be the source of an incoming data association to another task, so sometimes you have to duplicate the process variable.
Not all data mappings are so simple. Let's look at the Service task Insert Trade in the process model Execute Trade, below.
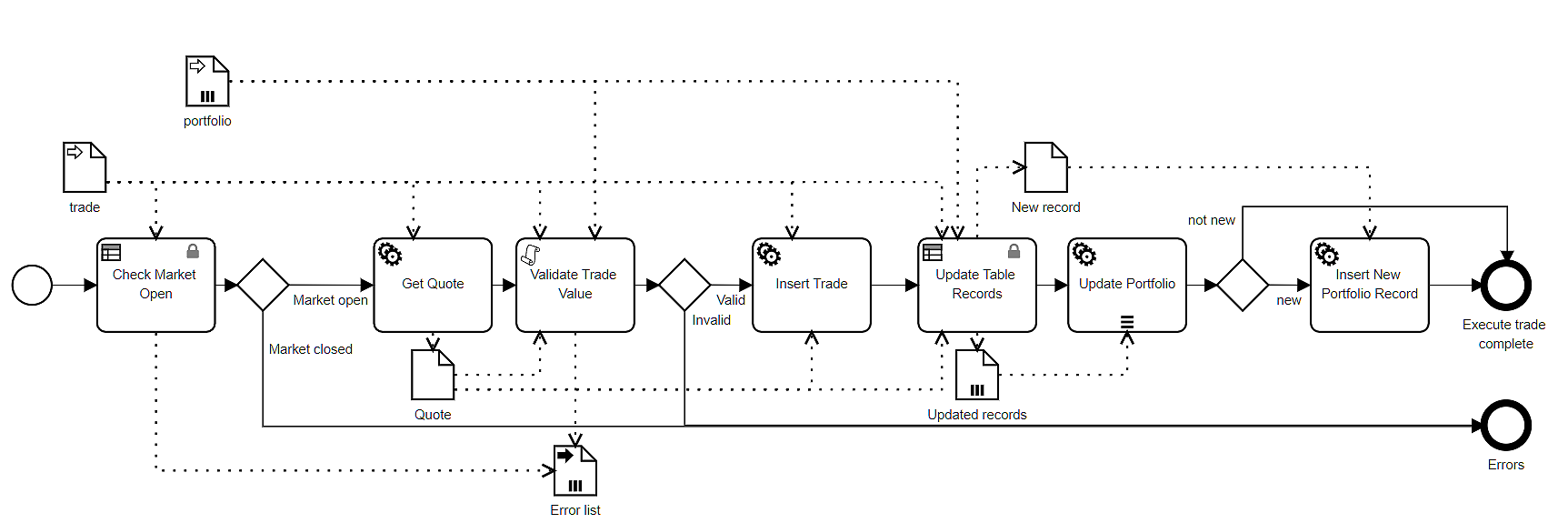
Insert Trade is bound to the OData operation Create trades, which inserts a database record. Its Operation Library entry specifies the task input parameter trade, type NS.trade, shown below.
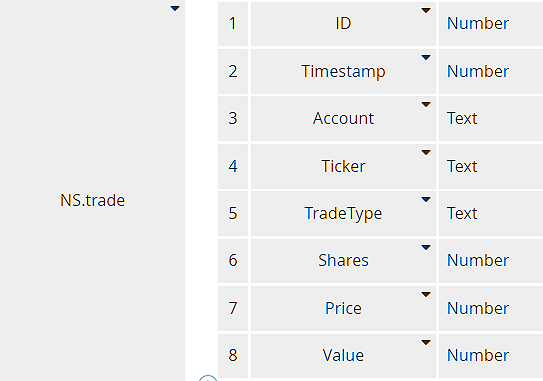
Actually, because the ID value is generated by the database, we need to exclude it from the Input Mapping. Also, the process variable trade uses a FEEL date and time value for Timestamp instead of the Unix timestamp used in NS.trade. We can accommodate these details by using a context in the Input Mapping instead of a simple literal expression. It looks like this:
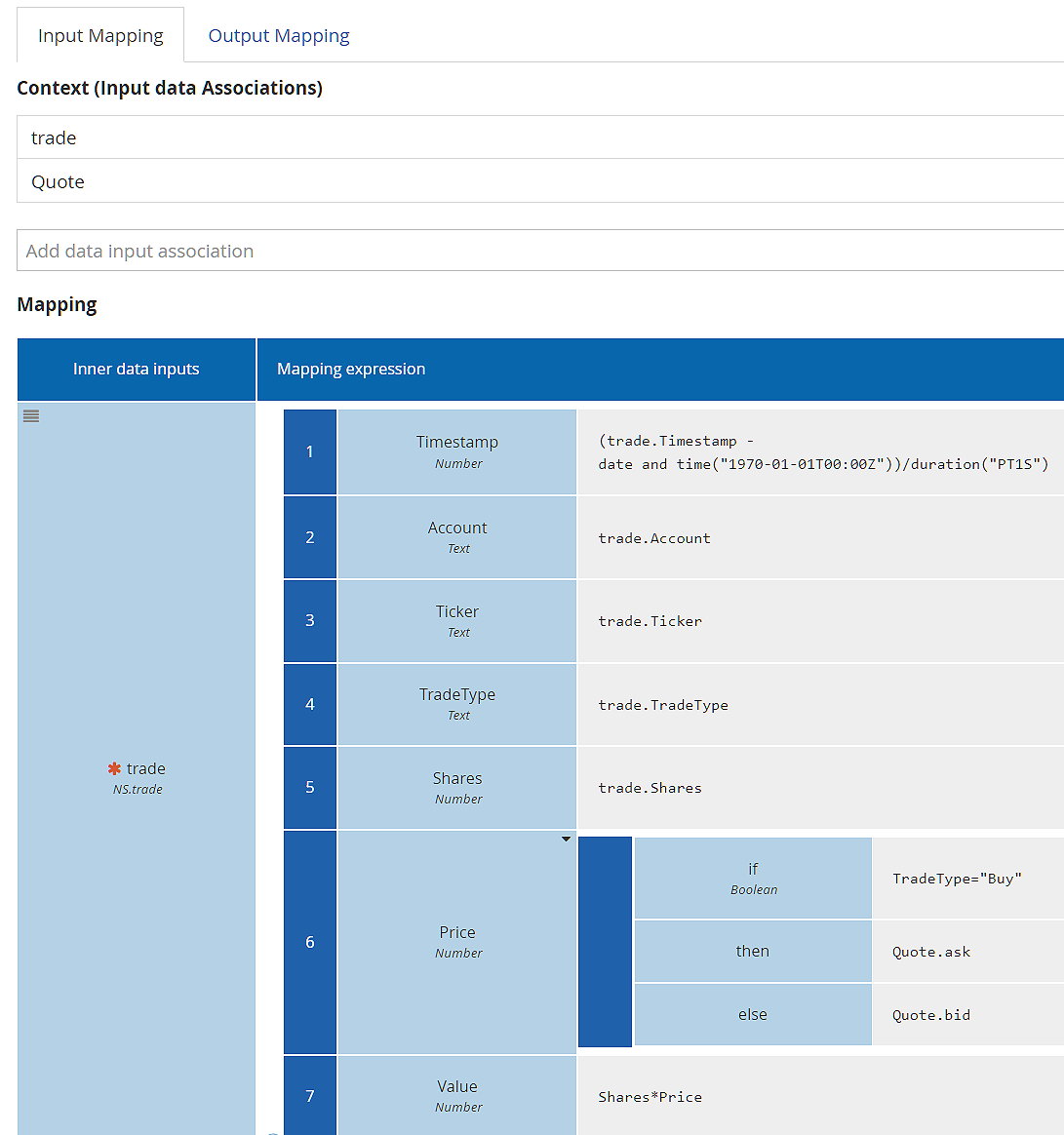
The context allows each component of the task input trade to be mapped individually from the process variables trade and Quote (which provides the price at the time of trade execution). As we saw with the Decision task, the Context section lists the available process variables, and the first column of the Mapping section lists the task inputs. Note also that the Price mapping uses the conditional boxed expression for if..then..else, new in DMN 1.4, designed to make complex literal expressions more business-friendly.
Finally, let's look at the Script task in this process, Validate Trade Value. Script and User tasks differ from the other task types in that the modeler actually defines the task inputs and outputs in the Data Mapping. On the Trisotech platform, a Script task has a single task output with a value determined by a single FEEL literal expression. As you can see in the process diagram, the process variables with incoming data associations to Validate Trade Value are trade, Quote, and portfolio, and the task output is passed to the variable Error list. This task checks to see if the value of a Buy trade exceeds the portfolio Cash balance or the number of shares in a Sell trade exceeds the portfolio share holdings.
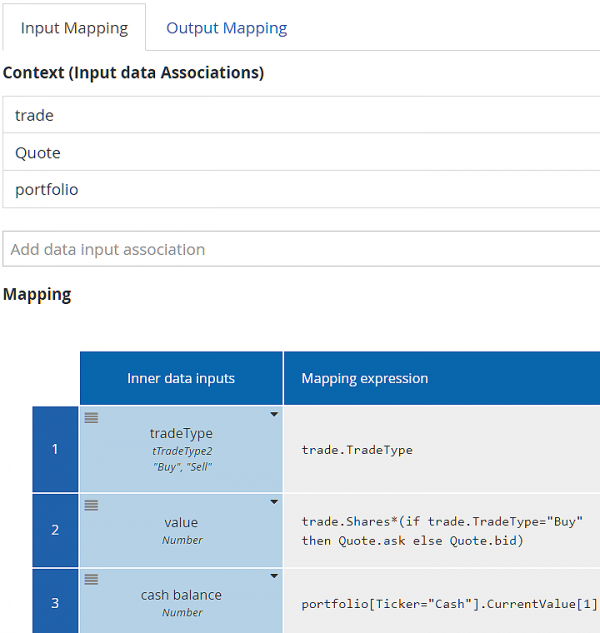
In the Script task Input Mapping, the modeler defines the names and types of the task inputs in the first column of the Mapping section. The mapping to those task inputs here are more complex literal expressions. The script literal expression references those task inputs, not the process variables. User tasks work the same way, except they are not limited to a single task output.
Hopefully you see now how data flow turns a non-executable process into an executable one. The triggering API call populates one or more process data inputs, from which data is passed via Input Mapping to task inputs. The resulting task outputs are mapped to other process variables (data objects), and so forth, until the API response is returned from the process data output. On the Trisotech platform, none of this requires programming. It's just a matter of drawing the data associations and filling in the Data Mapping tables using FEEL.
Follow Bruce Silver on Method & Style.













































































































































Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting