

If you need to create a large number of clinical models - either for a new project or to replace outdated software - then you are probably (or should be) feeling a bit overwhelmed. Such a project may take thousands of hours of coding, several informaticians, and many resources. Faced with such a daunting task it is no wonder that so many legacy systems persist for decades. However, there are ways to ease the burden and give you some control.
Working Smart
Sometimes people feel an urge to jump into model building right off the bat. This often results in working hard all through the project. Spending some time to plan and prepare can often to prove to be more efficient in the long run.
When building process or decision models, there are several ways to work smarter, such as:
- standardizing as much as possible
- controlling data and terminology proactively
- making use of patterns
- reusing models as much as possible
Standardization
Standardization is something that many people push back on. There are various reasons for this. Sometimes people feel that their domain is unique, and each solution must be individually crafted. While this attitude has some merits, it also increases the work needed to program your solution. The more that you standardize, the fewer the models that you need to develop and maintain, thereby increasing efficiency.
Sometimes you can standardize almost everything, but there are still a few variations between implementation sites that remain. A solution to this problem is to create what Trisotech calls a model "template", which allows different versions of a model to be tweaked for a specific site, while leaving most of the overall model otherwise unchanged.
Controlling Data and Terminology Proactively
Proactive control of data and terminology may seem insignificant compared to all the other tasks, However, if you do not have control of terminology and data when you start, then later stages of development can become a nightmare with a lot of wasted effort. For example, if you have multiple informaticians, then you will probably have multiple variable names all pointing to the same data object. Each name is interpreted by the software as being unique, and as such each must be linked to your data source. If you have control on your terminology, then you can reduce your data integration challenges by 50% or more.
Making Use of Patterns
When building clinical models, you may notice that the same tasks appear together over and over again. This is termed a pattern.
To illustrate this, let us look at preauthorization, which has 4 main decision tasks:
- identify any contraindications
- confirm indications of use
- establish any disease activity or severity requirements are met
- determine that alternative therapies have been tried and failed
All of these must be cleared before approval is granted. These tasks can be modeled in BPMN as follows:
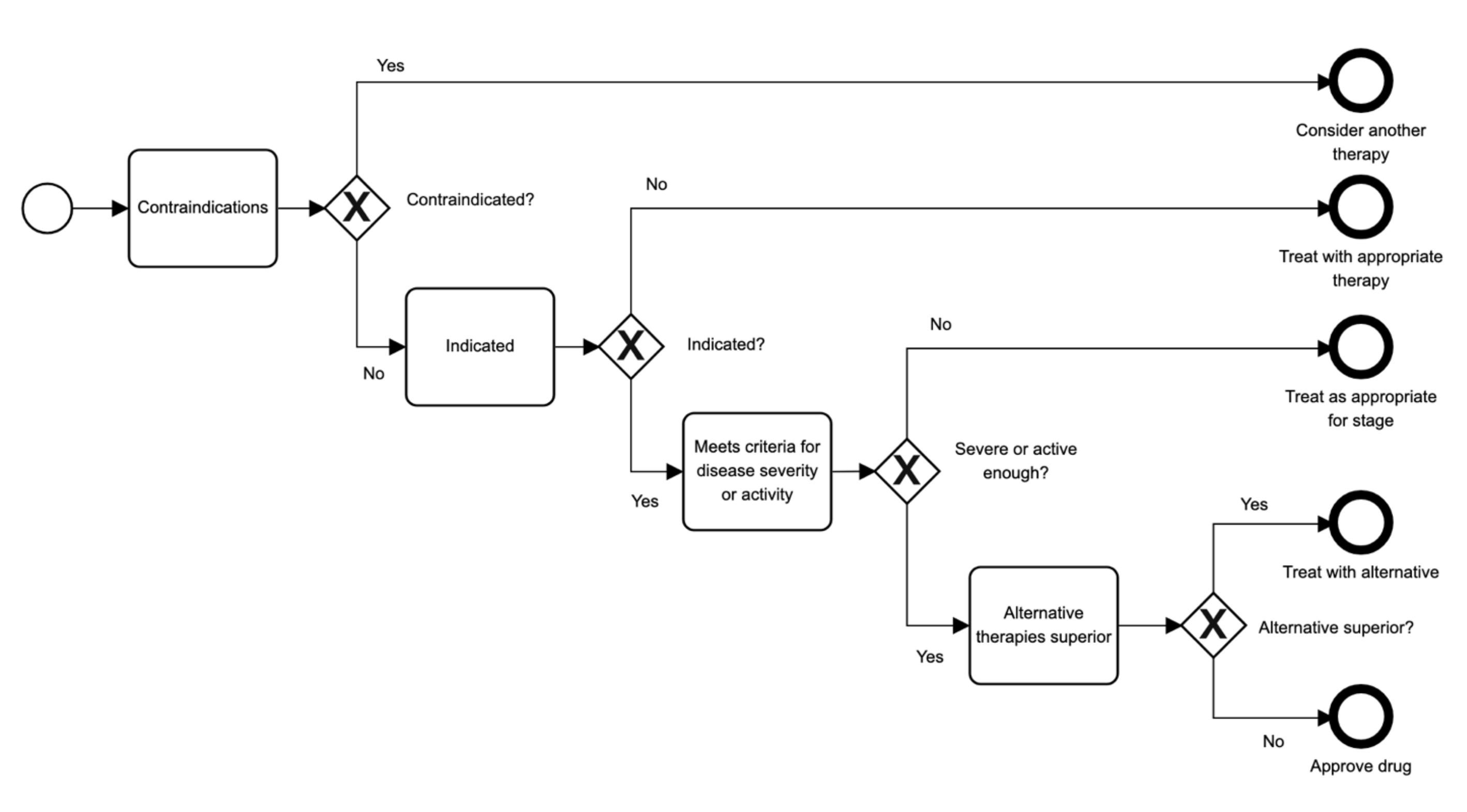
If you are a payer faced with preauthorizing drugs or services, then this one pattern can be used over and over again with minor variations. Using patterns can speed development when compared to treating each situation as a unique problem. In addition, users can better understand what you are trying to do.
Reuse
Once a model has been created, it can be used repeatedly. One goal of process and decision modelers is to create a library of models that can be re-used as building blocks in future projects.
When copying a model into another, the copy can occur in 2 ways:
- reuse by reference: the model is locked, with any changes to the source model propagated to all instances
- reuse by copy: model is unlocked, with changes kept local and not propagated back through all of the instances
Each approach has their pros and cons. Reuse by reference has many benefits since you do not have to go to each model that uses a particular decision to make any changes. However, to achieve this a good deal of standardization is needed.
Other ways to reuse a previously created knowledge include services or business knowledge models (BKMs).
Conclusions
Several strategies can be used to reduce the burden of programming burden without compromising quality. These require some careful thought and planning upfront, but they pay dividends over the long haul, speeding development and simplifying maintenance.













































































































































Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting