

In my recent post on the changing nature of work, I looked at some of the ways that the pandemic is changing how work gets done. Remote work, social distancing, removing physical documents from processes, and automation all play a part, but I also gave a brief mention to the analysis of processes:

Processes need to be analyzed and modeled in anticipation of automation, and to ensure that all required steps are still happening in a distributed environment. With workers scattered to different locations, and restrictions on personal interaction, this understanding is not going to happen through the usual analysis methods such as job shadowing or in-person interviews. Furthermore, processes will have changed, either explicitly or tacitly, in response to the distributed work environment. Instead, process mining (including desktop agents that monitor user actions across multiple applications) will be a critical tool for business analysts.

This will be a radical shift for many business (process) analysts. Currently, some business analysts do little analysis at all, but provide more of a business documentation function. This may be due to lack of training to provide them with the required analytical skill set, or could be the organization’s view of the business analyst role as a documenter rather than an innovator. Documenting current processes and procedures is valuable, but it’s not really analysis, and it is unlikely to discover opportunities for radical improvement. Because of this view of business analysts as documenters, many are provided only with documentation tools: modeling tools for building BPMN, CMMN and/or DMN models of their processes and decisions; wireframe or other diagraming tools for sketching user interfaces; and the usual suite of office productivity tools for writing text-based descriptions of their findings.
Gathering information as input to this documentation is typically done through observation: job-shadowing someone while they perform a task (which is useful for task procedures but not overall process flow), interviewing teams about their operational processes (which is often of very little use because of the subjectivity and interpretation of the interviewees), or viewing operational metrics (which show what is measured but not necessarily aligned with corporate goals). At the end of this information gathering, the business analyst is left with an incomplete and/or incorrect view of what actually happens, and may have little understanding of how the processes link to goals.
I don’t want to downplay the role of in-person observations – I’ve made a lot of use of these techniques over the years, and they can provide insights – but to identify that they don’t do a very complete job of analysis, and they should only be one part of the data gathered. With the current remote work and social distancing, most observations need to be done remotely, which adds an extra filter between the observer and the task performer.
As a starting point for a more complete, data-driven analysis, it’s important to gain understanding of the actual end-to-end business process, both the human tasks and the activities in the systems with which they interact. This can be done using analytical process discovery techniques, namely process mining and task mining, which measure what really happens rather than someone’s interpretation of what happened (or was supposed to happen).
Process mining tools take history logs from systems such as ERP and CRM systems, then automatically derive the end-to-end process models. But rather than just providing a single process model, process mining shows all the different ways that the process is actually executing, and helps identify the reasons for the variance. This is a great way to find the broken processes, where someone looks at the discovered process and says “I didn’t know that we did that”, or to show situations where people have been able to bypass certain controls, such as issuing a PO without the right level of approval.
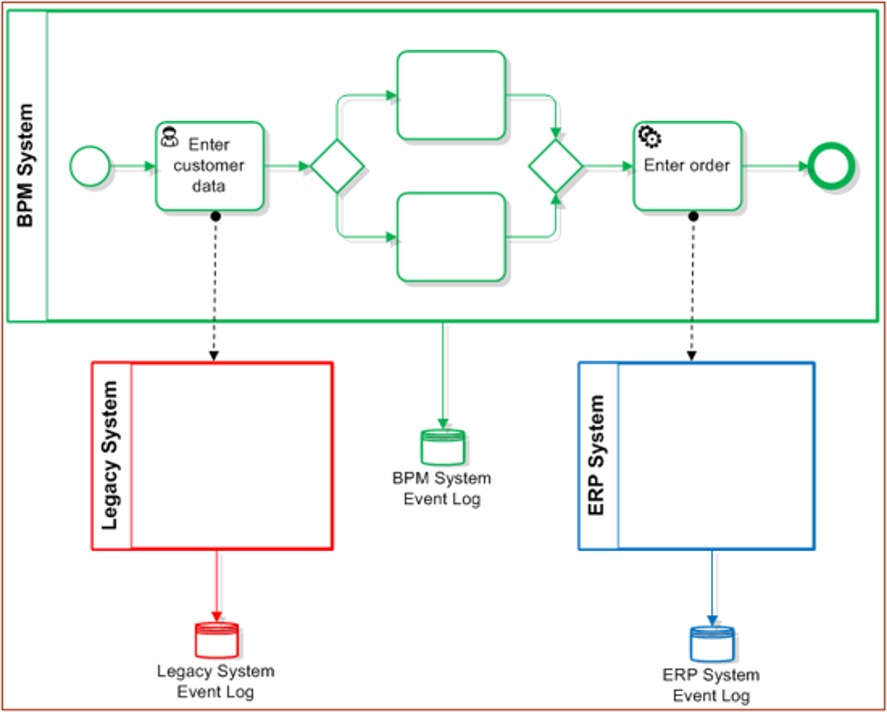
Taking a brief look at how process mining works, we have a business process management system (in green) that is orchestrating several tasks, including a user task to enter customer data that will link to our legacy customer information system at the lower left (in red), and a service task that will push order information to our ERP system at the lower right (in blue). Each of these systems has their own history log that tracks events for audit purposes, but we’re going to exploit that history log to figure out how the process works overall.
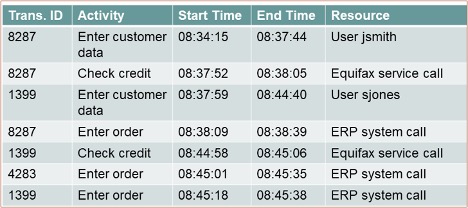
Taking a look at the history log from the BPM system, it has a unique transaction or case ID, then the activity name (which is the stage that we are at in the BPM process), the start and end time for the activity, and the resource that performed the activity. Trace through for case number 8287, and you’ll see the first activity at 8:34:15 is when jsmith is assigned a task to enter customer data in the non-integrated legacy system; he goes to the legacy system screen and enters this information, then marks the task as complete in the BPM system. Then, there is an automated service call to check the customer’s credit at 8:37:52, which would be one of those unmarked steps in the middle of the BPM system workflow. Another activity on another case is the next thing in the history log, but we’re only interested in case 8287, so skip down and we have a call to the ERP system at 8:38:09 to enter the order.
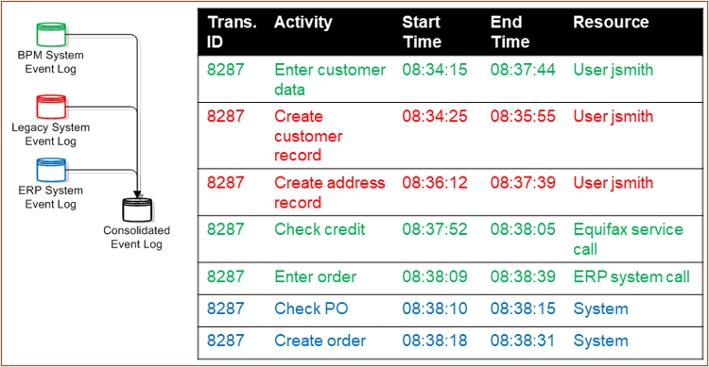
The important thing is that each of the systems has their own history log, but that they can be reconciled if they all use the same case number. Here’s the complete list of activities for what happened with case 8287 across all three systems. In green, we see the activities from the previous BPM system log. But in between those activities, we see the legacy system history log in red where the customer and address records were created. Then, in blue, we see the ERP system history log where the PO was checked and the order created. This is the consolidated history of everything that happened to case 8287 from start to finish. In reality, there will be many more records from each of the three systems showing more fine-grained activities.
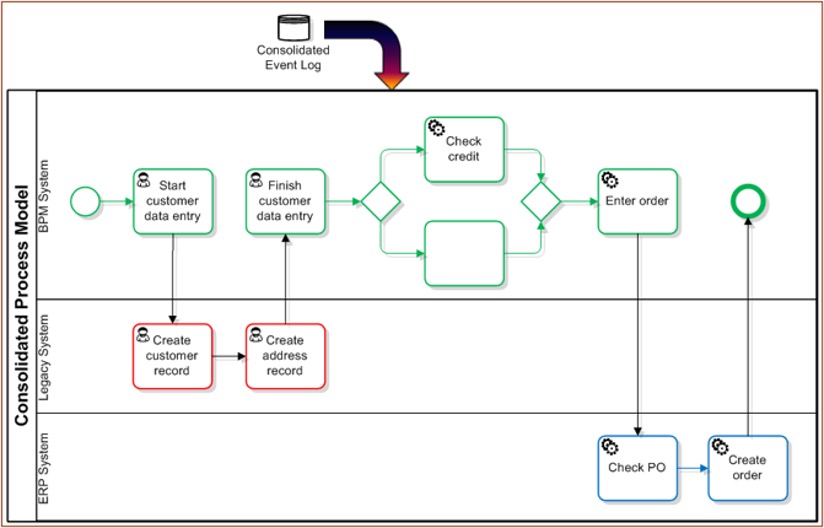
Now that we have the consolidated history log for case 8287 and every other case in the system, the process mining algorithms can derive the process model from these records. I’ve shown it here as a BPMN diagram with swimlanes for each system, but usually it looks more like the discovery graph that you’ll see in process mining tools.
Task mining is technically a lot like process mining, but it uses data collected by tracking the user actions on their computer; once that data is collected, the algorithms to derive the process models are very similar. For example, task mining can find all the copy and pastes that users do between systems, and data entry to different applications. Task mining helps identify opportunities for automating tasks, such as when the user always copies three fields on one application screen into three fields on another screen: this is definitely not a good use of a skilled knowledge workers’ time, and could benefit from task automation.
The advantage of using process and task mining over manual process modeling is that it’s data-driven: the processes discovered are the actual operational processes, not someone’s interpretation of those processes. It also includes statistical information such as the frequency and duration of each activity and pathway in the process, allowing for much more detailed analysis based on the data. This is where data-driven techniques including conformance checking and root cause analysis can be used to find the problems in the processes, and figure out what is causing the problems.
Once you’ve discovered the actual processes, analyzed them to determine what they should be and modeled those future-state processes, the next step is to simulate those processes to see what impact those changes will have.
Simulation lets you do “what if” analysis on your processes without actually changing the real-world processes.
- Where would work pile up if our throughput volume was drastically increased?
- What resources would sit idle if it was drastically decreased?
- If two parts of the process ran in parallel, how would that impact the end-to-end cycle time?
- If a human task was automated using robotic process automation, how much time and money would that save?
The outcomes of simulation help us to understand how we trade off between cost and cycle time, and figure out the best way to allocate resources within processes.
In times of rapidly-changing processes, such as we have now with changing supply chains and a shift to remote work, organizations need much greater analytical strength to figure out how to rewrite their processes into something completely new. If you’re a business analyst, this is the perfect time to ask yourself if you – and your organization – could benefit from using more data-driven analysis to figure out what you’re doing, and what you should be doing.
Maximize cross-selling and up-selling with the Digital Enterprise Suite













































































































































Learn how it works
Request DemoConfirm your budget
Request PricingDiscuss your project
Request Meeting